概念
Gradient Boosting Decision Tree又叫 MART(Multiple Additive Regression Tree),一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案,即其中的树为回归树而不是分类树(分类树累加无意义)。它在被提出之初就和SVM一起被认为是泛化能力(generalization)较强的算法。
主要由三个概念组成:1、Regression decision Tree(DT、RT);2、Gradient Boosting(GB);3、Shrinkage(缩减)。
GBDT的核心在于累加所有树的结果作为最终结果,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。这就是Gradient Boosting在GBDT中的意义,残差的意思就是: A的预测值 + A的残差 = A的实际值
Shrinkage
Shrinkage(缩减)的思想认为,每次走一小步逐渐逼近结果的效果,要比每次迈一大步很快逼近结果的方式更容易避免过拟合。即它不完全信任每一个棵残差树,它认为每棵树只学到了真理的一小部分,累加的时候只累加一小部分,通过多学几棵树弥补不足。
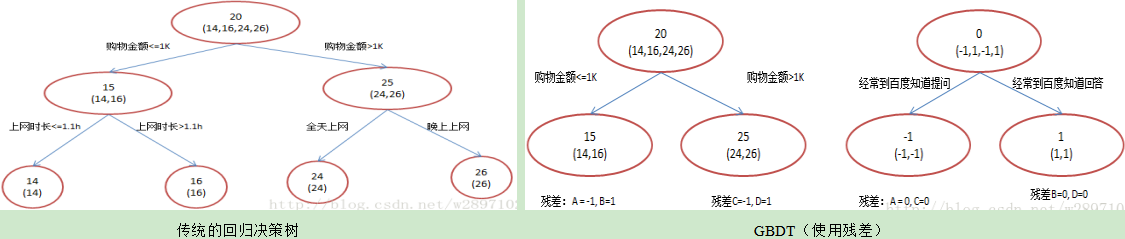
例子:年龄预测,简单起见训练集只有4个人,A,B,C,D,他们的年龄分别是14,16,24,26。其中A、B分别是高一和高三学生;C,D分别是应届毕业生和工作两年的员工。结果如下两图所示。
传统的回归决策树和GBDT的结果一样,为何还需要GBDT呢
答案是过拟合。过拟合是指为了让训练集精度更高,学到了很多”仅在训练集上成立的规律“,导致换一个数据集当前规律就不适用了。其实只要允许一棵树的叶子节点足够多,训练集总是能训练到100%准确率的(大不了最后一个叶子上只有一个instance)。在训练精度和实际精度(或测试精度)之间,后者才是我们想要真正得到的。
我们发现图1为了达到100%精度使用了3个feature(上网时长、时段、网购金额),其中分枝“上网时长>1.1h” 很显然已经过拟合了,这个数据集上A,B也许恰好A每天上网1.09h, B上网1.05小时,但用上网时间是不是>1.1小时来判断所有人的年龄很显然是有悖常识的;
相对来说图2的boosting虽然用了两棵树 ,但其实只用了2个feature就搞定了,后一个feature是问答比例,显然图2的依据更靠谱。(当然,这里是LZ故意做的数据,所以才能靠谱得如此狗血。实际中靠谱不靠谱总是相对的) Boosting的最大好处在于,每一步的残差计算其实变相地增大了分错instance的权重,而已经分对的instance则都趋向于0。这样后面的树就能越来越专注那些前面被分错的instance。就像我们做互联网,总是先解决60%用户的需求凑合着,再解决35%用户的需求,最后才关注那5%人的需求,这样就能逐渐把产品做好,因为不同类型用户需求可能完全不同,需要分别独立分析。如果反过来做,或者刚上来就一定要做到尽善尽美,往往最终会竹篮打水一场空。