
Bagging
一种要求“不稳定”的投票分类方法:从数据集中有放回地抽取N个实例组成训练集,训练得到一个模型,多次抽取的样本集彼此相似,但源于随机性有稍有不同。经过多次样本抽取与模型训练后得到多个模型。使用时,对于未知样本X分类,每个模型都得出一个分类,得票数最高的即为样本X的分类。
不稳定:数据集的小的变动能够使得分类结果显著的变动
Boosting
在提升中,我们通过在前一个学习器所犯的错误上训练下一个学习器,积极地尝试产生互补的学习器。所谓的弱学习器是误差概率小于1/2的学习器。
步骤:
-
给定一个大训练集。随机n1<N个样本,作为训练集X1来训练d1。
-
随机抽取n2<N,然后将d1中判断错误的样本结合n2作为训练集X2来训练d2。
-
抽取d1和d2分类不一致的样本作为训练集X3。
-
校验:给定一个实例我们首先将其提供给d1和d2;如果二输出一致,这就作为输出结果,否则d3的输出作为结果。
已证明整个系统降低了错误率,但缺点是明显依赖于数据和基学习器: 需要一个比较大的训练集,并且基学习器应当是弱的但又不是太弱,而且提升对噪声和离群点尤其敏感。
样本的权重:
-
没有先验知识的情况下,初始的分布应为等概分布,也就是训练集如果有N个样本,每个样本的分布概率为1/N
-
每次循环一后提高错误样本的分布概率,分错样本在训练集中所占权重增大, 使得下一次循环的弱学习机能够集中力量对这些错误样本进行判断。
弱学习机的权重:准确率越高的弱学习机权重越高。
循环控制:损失函数达到最小,在强学习机的组合中增加一个加权的弱学习机,使准确率提高,损失函数值减小。
ps:adaboost算法是属于boosting算法的改进。
adaboost
提升的一个变种,其中重复使用相同的训练集因而不要求数据集很大。AdaBoost还可以组合任一数量的基学习器(常见的是使用简单的矩形特征(Haar-like)、决策树);其思想是将实例抽取的概率修改成误差的函数。
步骤:

一旦完成训练,AdaBoost就采用投票方法,给定一个实例,所有的决定其分类,而后取一个加权的投票结果,其中权重与基学习器(在训练集上的)准确率成正比: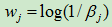
Adaboost算法目的:使用训练样本集对多个弱分类器(或说基学习器)进行训练(得到最佳阈值)并筛选,得到各个分类器的正确率,小于1/2的舍去,大于1/2的留下,并根据正确率大小赋予相应的权值,采用加权投票组合成一个强分类器。其训练思想为将实例的抽取概率改成误差的函数。
个人理解:
在人脸检测中,在全部的haar-like特征都提取完后,需要进行弱分类器的筛选与训练(得到最佳阈值),筛选和训练的过程是adaboost中完成。
取一个弱分类器,按样本抽取的概率分布取N个样本对该弱分类器进行训练,得到最佳阈值的同时调整样本抽取概率,在训练好后,若该分类器的识别率在50%以上,则留下,否则舍去。继而进行下一个弱分类器的训练和筛选,同时对加权组合的强分类器的识别结果作判断,若满足要求则不再增加弱分类器到该强分类器中,转而对下一个强分类器进行生成。