
最大后验估计

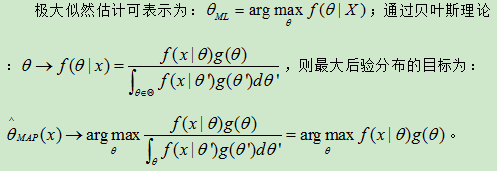

| 如果我们没有理由偏爱的某个值,即若先验密度是扁平的,则后验将于似然f(X | theta)有同样的形式,并且MAP估计将等价于最大似然估计。 |
MAP估计器是比ML估计起更深层次的估计:a)ML估计起基于贝叶斯范式的极端,忽略了先验信息; b)ML估计器仅仅依赖于观测模型,因而可能导致非唯一解为了加强唯一性和稳定性,先验必须被合并到估计器的规划中,这正是MAP估计起要做的。
-
例子(重点):
假设有五个袋子,各袋中都有无限量的饼干(樱桃口味或柠檬口味),已知五个袋子中两种口味的比例分别是:樱桃100%; 樱桃75% + 柠檬25%; 樱桃50% + 柠檬50%; 樱桃25% + 柠檬75%; 柠檬100%;
问从同一个袋子中连续拿到2个柠檬饼干,那么这个袋子最有可能是上述五个的哪一个?
使用极大似然估计解:假设从袋子中能拿出柠檬饼干的概率为p,其中的参数对应着袋子,则似然函数可写作:p( 两个柠檬饼干 袋子 ) = p*p,而p的取值是一个离散值,即上面描述中的0,25%,50%,75%,1;我们只需要评估一下这五个值哪个值使得似然函数最大即可,得到为袋子5。这里便是最大似然估计的结果。 拓展:最大似然估计有一个问题,就是没有考虑到模型本身的概率分布,下面我们扩展这个饼干的问题。假设拿到袋子1或5的机率都是0.1,拿到2或4的机率都是0.2,拿到3的机率是0.4,那同样上述问题的答案呢?这个时候就变MAP了。
我们根据公式,MAP函数则可写成(pp)g,p的取值分别为0,25%,50%,75%,1,g的取值分别为0.1,0.2,0.4,0.2,0.1.分别计算出MAP函数的结果为:0,0.0125,0.125,0.28125,0.1。则结果为第4个袋子。